GP non-linear identification
Overview
The main idea of this work is to establish a control strategy for a non-linear process. The workflow consists of the following steps:
- Data Collection: Collect input-output data from the non-linear process model described below.
- Model Identification: Perform a non-linear model identification using Genetic Programming (GP):
- Algorithm Details: The algorithm builds a discrete-time non-linear state-space model by evolving symbolic expressions (trees) for state transitions and outputs. It utilizes a predefined function set (including standard arithmetic and safe versions of nonlinear functions like exp, log, and tanh) and an evolutionary approach with crossover, mutation, tournament selection, and elitism. It also applies penalties for excessive complexity (bloat) and unused terminals to find an optimal balance between model accuracy and structural simplicity.
- Model Predictive Control (MPC): Use this identified GP model within an MPC framework to predict future states and control the process.
- Optimal Input Computation: Because the resulting non-linear model will most likely be unsuitable for standard analytical backward input computation (e.g., standard gradient-based optimization might get stuck in local minima or be mathematically intractable), a GP-like heuristic method is planned to calculate the optimal process inputs during the MPC execution.
Process model to be used
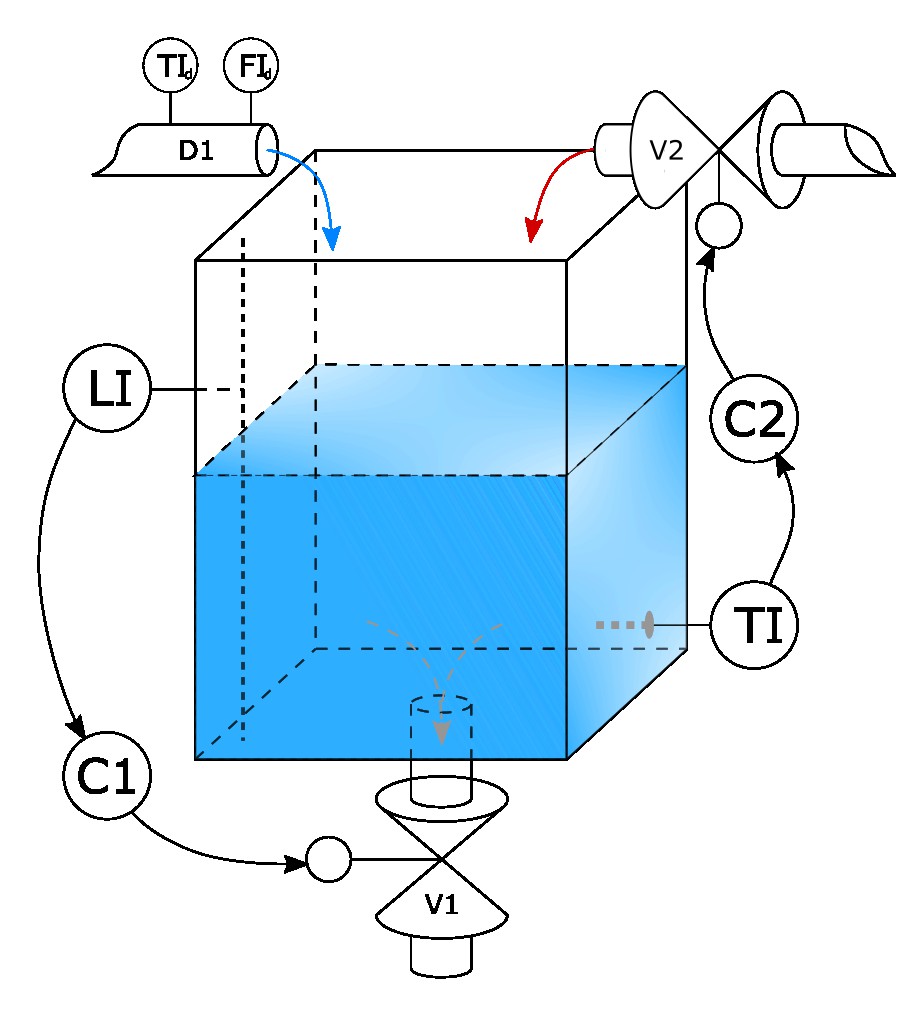
The process is a simple first principal model of a water tank. The tank dimensions in meters () are . It has uncontrolled measured inlet water flow () with measured temperature (). It is possible to manipulate tank water level by setting position for the outlet valve between and ( to ) and manipulate temperature inside tank by setting position of hot water inlet valve in the same range. Valves opening/closing speed is limited to () as real world valves cannot be opened or closed immediately and have some traveling time. Both valves have linear characteristics meaning that valve position in per cents is equal to the area of the valve opening in per cent (e. g. if valve maximum opening area is then position means that opening area is ). At the same time water flow through the opening depends on the pressure before the valve. In case of valve the pressure depends on the water level in the tank – the higher is the level the bigger is the water flow through the same opening. This makes effect of to the process to be nonlinear. In case of it is assumed that pressure before valve is constant ( or ). Hot water temperature is fixed at the value of .
Identification data collection
Simulation step tests were manually generated to keep tank level in between minimum and maximum values.
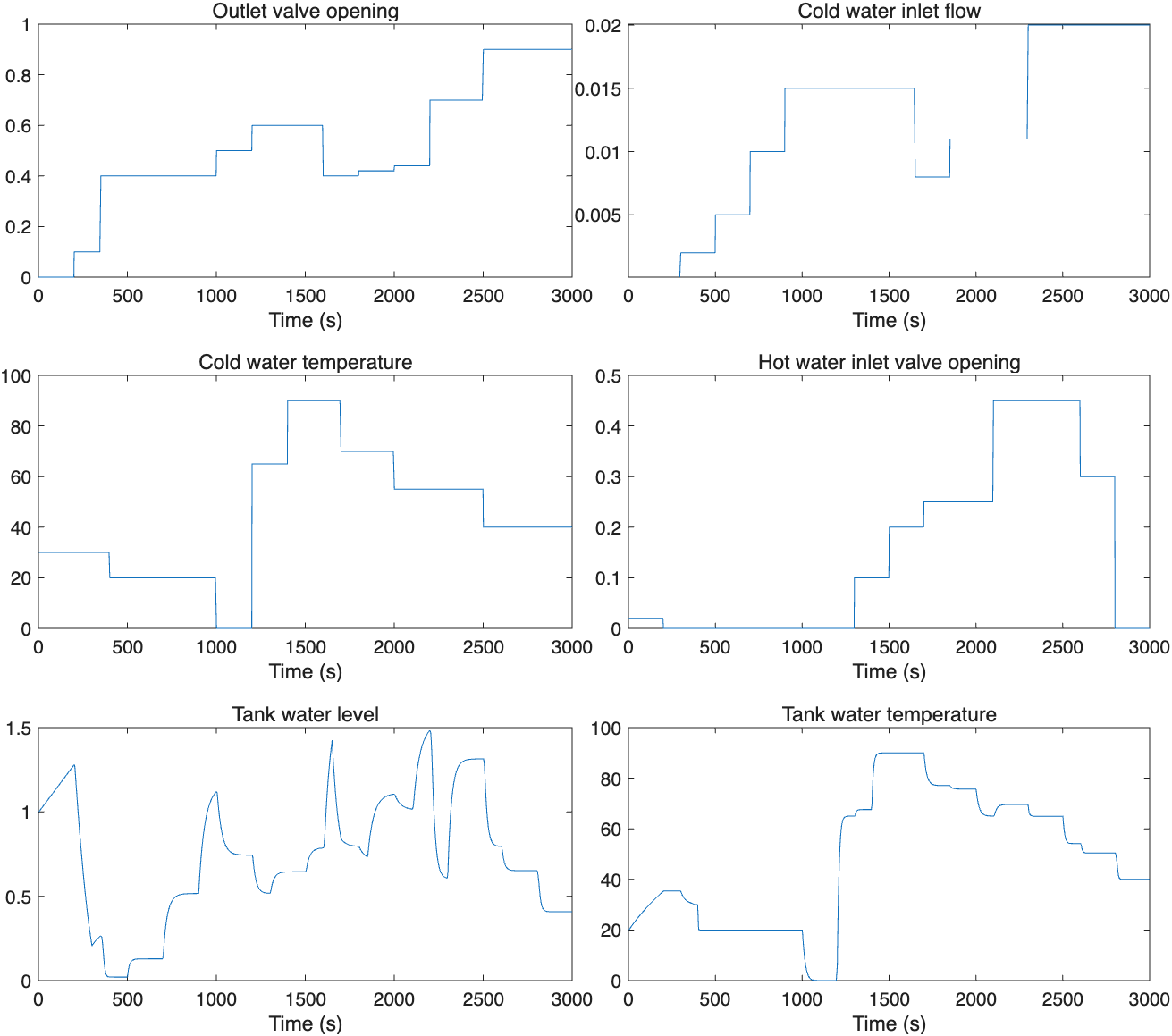
Inputs are: 1. Outlet valve posiotion; 2. Inlet flow; 3. Inlet temperature; 4. Inlet hot valve position.
Outputs are: 1. Tank level; 2. Tank temperature.
Input data generation script is generate_input_data.m. Data includes 3000 samples with sample time.
Identification algorithm
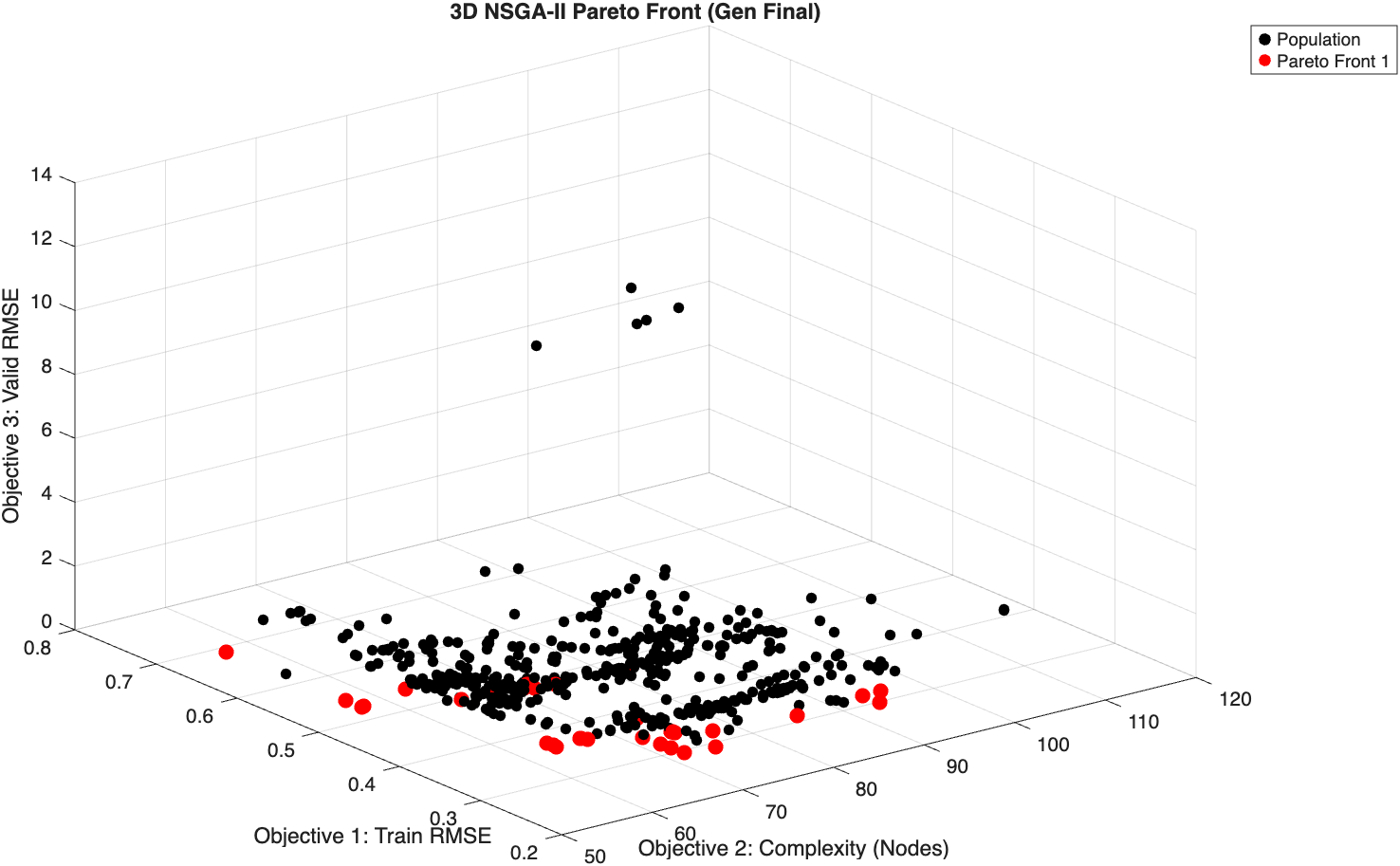
This code uses a Multi-Objective Genetic Programming (MOGP) algorithm (NSGA-II) distributed across an Island Model architecture to automatically discover the mathematical equations of a nonlinear state-space system from input-output data. It acts as a Grey-Box identifier by injecting known physical equations as protected structural seeds, and uses Memetic optimization (BFGS or Nelder-Mead) to continuously fine-tune the constants, ultimately finding the Pareto-optimal models that balance predictive accuracy (RMSE) against equation complexity (BIC).
Identitification exmample
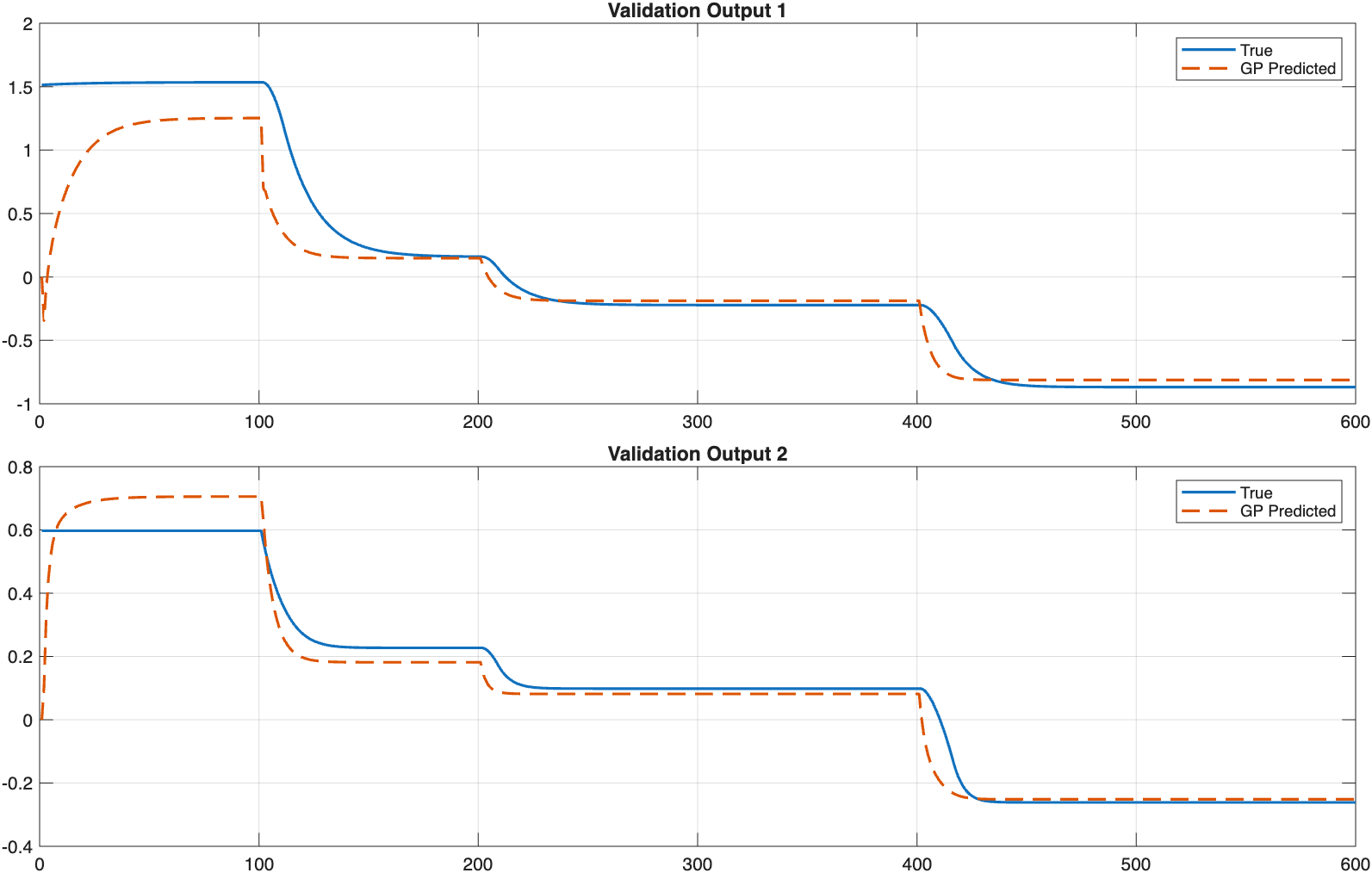
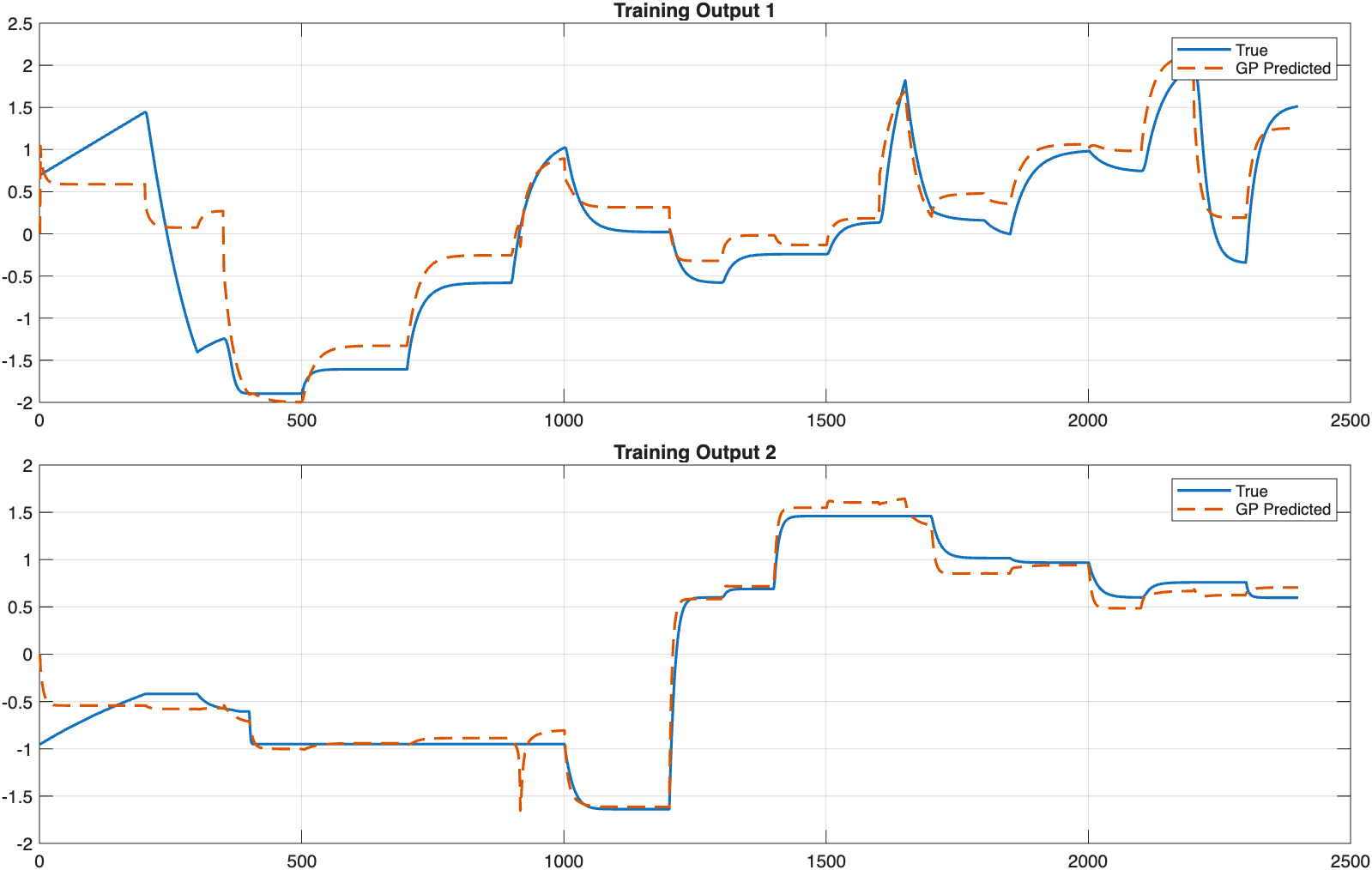
FINAL BEST MODEL: TrainRMSE=0.3004, ValRMSE=0.2073
Best expression trees:
State 1:
State 2:
State 3:
State 4:
Output Matrix C:
1. Pareto Front
2. Training Data Fit
3. Validation Data Fit